Most of the largest AI models running today don’t use all their parameters when they answer you.
The short answer
A mixture of experts (MoE) model splits its neural network into multiple specialized sub-networks, called experts, and uses a learned router to activate only a small subset of them for each input token. Instead of every parameter firing for every token, only the relevant slice lights up. This makes large models faster and cheaper to run than their raw parameter counts suggest, and it explains why frontier AI has gotten dramatically cheaper to serve over the past two years.
The long answer
How a conventional dense model processes tokens
In a standard transformer-based language model, every forward pass activates every parameter. Feed in a token and the full weight matrices do work on it, regardless of what the token is. At smaller model sizes this is manageable. At 70 billion or 100 billion parameters, the compute cost per token becomes significant. You’re running the equivalent of a small country’s calculator fleet for every single output token, whether the word is “the” or a rare technical term that plausibly needs more processing.
Dense models scale well up to a point, but the compute requirements grow proportionally with parameters. There’s no free lunch built into the architecture.
What “experts” actually are
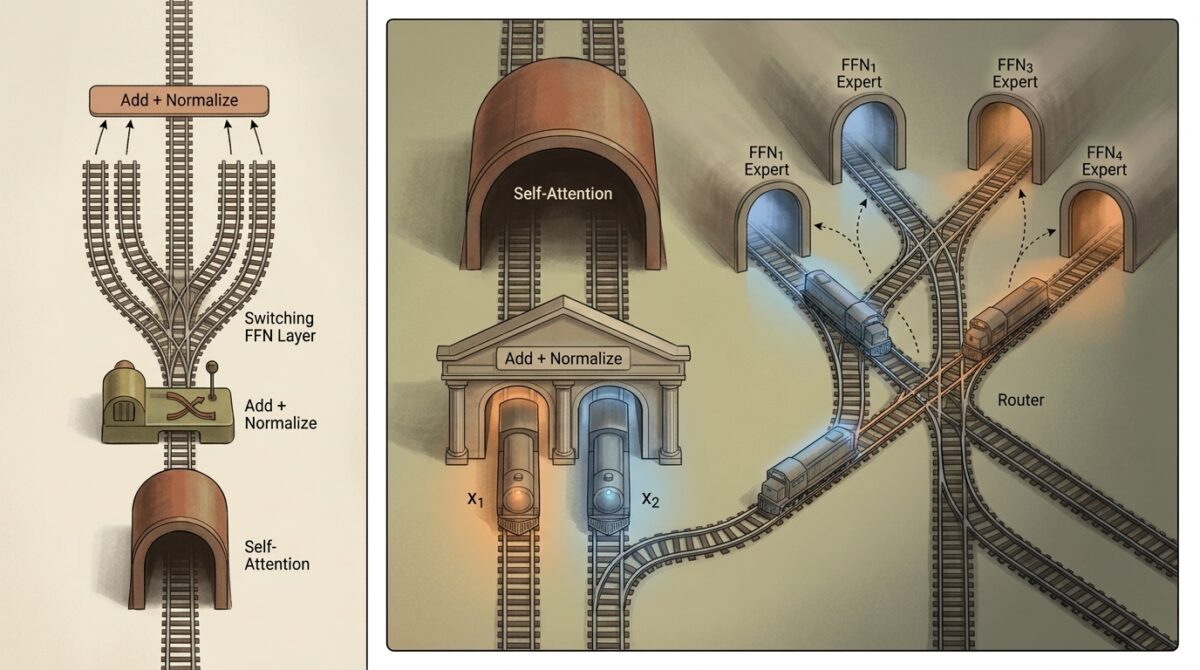
In an MoE model, the dense feed-forward layers inside each transformer block are replaced by a set of parallel sub-networks: the experts. Structurally, each expert resembles the feed-forward network (FFN) you’d find in a conventional dense model. The difference is that instead of one giant FFN doing all the work, you have multiple smaller FFNs that the model can route tokens through selectively.
These experts aren’t hand-labeled or manually assigned subject areas. The model discovers its own routing patterns during training. Researchers have found that experts do develop behavioral specializations, though what those specializations look like from the outside isn’t always obvious. Some studies find syntactic or structural patterns. Others find topic-adjacent clustering. It varies by model and training setup.
What matters functionally is that the model learns to send different tokens to different experts, and the result is a distributed system that performs well across diverse inputs without requiring every component to handle every input.
The router
Between the attention layer and the experts sits a gating network, called the router. It takes the current token’s representation and outputs a probability distribution across all available experts. The model then selects the top-K experts (most commonly top-2) and routes the token through those and only those.
The outputs from the selected experts are weighted by their probability scores and combined to produce the layer’s final output. The rest of the experts do no work on that token.
As HuggingFace’s overview of MoE architectures explains, the routing decision happens independently at each layer, which means a token might go through different expert combinations at different depths of the model.
Active vs total parameters: the core trade-off
Mixtral 8x7B, released by Mistral AI in early 2024, demonstrates the architecture concretely. The model has 46.7 billion total parameters. But only 12.9 billion parameters are active per token, because the top-2 routing means only 2 of the 8 experts process any given input.
That gap is the whole point. You pay the training cost across all 46.7 billion parameters: every expert needs to learn something useful, every expert participates in gradient updates. But you pay the inference compute cost against roughly 12.9 billion active parameters per token. The result is a model that competes with much larger dense models on benchmarks, while running inference at speeds and costs closer to a 12-13B dense model.
This ratio between total and active parameters is now one of the key dimensions to understand when evaluating a model, separate from either number taken alone.
Load balancing and expert collapse
MoE training has one characteristic failure mode: if the router learns to favor one expert overwhelmingly, that expert gets the bulk of the gradient signal and improves, while the others receive little signal and stagnate. You end up with one expert doing most of the work, which defeats the purpose.
To prevent this, MoE training adds an auxiliary load-balancing loss that penalizes the model when traffic to experts becomes too unequal. The goal is to keep utilization distributed across the available experts.
The tradeoff is real: too aggressive a load-balancing constraint forces tokens to sub-optimal experts for the sake of fairness, which hurts quality. Too permissive and you risk collapse. Papers in this area treat the balance between quality and utilization as a live research problem, not a solved one.
The memory constraint
Here’s what consistently surprises people. MoE models have lower compute requirements per inference step, but their memory requirements don’t shrink proportionally. All 46.7 billion parameters of Mixtral 8x7B need to sit in GPU memory, even though only 12.9 billion are doing active computation on any given token.
You need the VRAM to hold the full model. A GPU that can comfortably run a 13B dense model can’t run Mixtral 8x7B without quantization. The compute savings are real, but memory footprint stays tied to total parameter count, not active parameter count. Local deployment planning has to account for this gap.
Why this matters in 2026
MoE is no longer experimental. Several of the most capable models publicly available use this architecture. Grok 1 from xAI is a confirmed MoE with 8 experts. DeepSeek V2 uses a refined variant called DeepSeekMoE that further separates shared from routed experts.
The pattern across all of them is the same: sparse activation allows teams to build models with far more total capacity than they could deploy economically as dense architectures. The representational richness of a very large model, at inference costs closer to a smaller one.
For developers and businesses in Africa integrating AI via API, this matters for a direct reason. The economics of sparse inference are better than dense inference at comparable capability levels. When frontier providers run enormous models behind APIs and still offer declining prices, MoE architecture is part of how that’s possible. The technology isn’t abstract: it’s in the cost structure of tools you’re already using.
The practical implication: stop comparing models by total parameter count as a proxy for capability or cost. A large MoE and a smaller dense model can be similar in inference cost while being very different in capability. Understanding which dimension matters for your use case requires knowing what kind of model you’re working with.
Common misconceptions
“Experts specialize by topic.” Appealing intuition, but not quite right. Experts do develop behavioral patterns, but they’re not cleanly sorted by subject matter in most analyses. You can’t say “expert 3 handles legal text” with confidence. The specializations are subtler and less interpretable than that.
“MoE always beats dense models of the same total size.” The advantage of MoE is in matching performance while reducing inference FLOPs, not in getting more capability from a fixed parameter budget. A well-trained dense model at equivalent active parameters is competitive.
“You can run a large MoE with the same memory as a model of its active size.” Wrong. Memory scales with total parameters. Compute scales with active parameters. People confuse these constantly. Plan for total size when estimating VRAM requirements.
“GPT-4 is definitely a MoE.” Plausible but unconfirmed by OpenAI. Architecture details for most frontier models remain proprietary. Speculating that all frontier models are MoE because some are is an inference error.


